作者:國工智能項目部—林鋒
前言
面對市場競爭的日益激烈,制造企業想要得到客戶的認可,不得不從價格優勢轉向高質量的產品優勢。產品質量的高低已經關系到企業核心競爭力的重要一環。如何有效地管理和利用這些從企業生產和經營中產生的龐雜的質量數據,是企業迫切需要解決的問題。
將數據挖掘技術應用于生產過程質量管理中,挖掘出生產過程中影響質量的關鍵因素及其內在聯系,有針對性地采取預防措施,從而提高產品質量,為企業持續改善質量提供決策支持。在實際工作中,為了避免漏掉某些重要因素,往往在一開始選取指標的時候盡可能考慮所有的相關因素,而這樣做的結果,則是變量過多,變量間的相關度較高,給統計分析與建模帶來極大不便,因此人們希望能夠研究變量間的相似關系,按照變量的相似關系把他們聚合成若干類,進而找出影響系統的主要因素,引入了變量聚類方法。
含義
根據不同變量之間相關程度高低進行分類。研究中,若變量較多且相關較強時,可以使用變量聚類法把變量聚為幾個大類,同一類變量之間有較強相關性,不同類變量之間相關程度低,并可以從同類變量中找出一典型性變量作為代表,最終減少變量個數達到降維目的。
案例
有10種500毫升啤酒的成分和價格等數據,試用變量聚類對變量進行聚類以達到縮減變量的目的,篩選出預測變量。數據的變量包括熱量、鈉含量、酒精含量、價格、麥芽濃度。
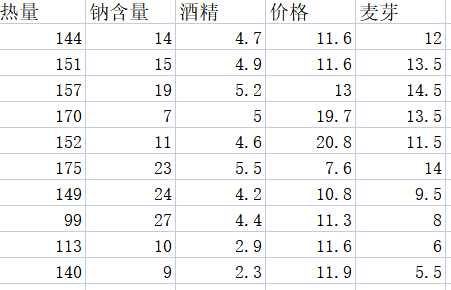
分析過程
從數據大腦中的組件面板查找變量聚類組件,拖到到工作面板,配置數據源以及變量聚類組件參數,點擊運行。

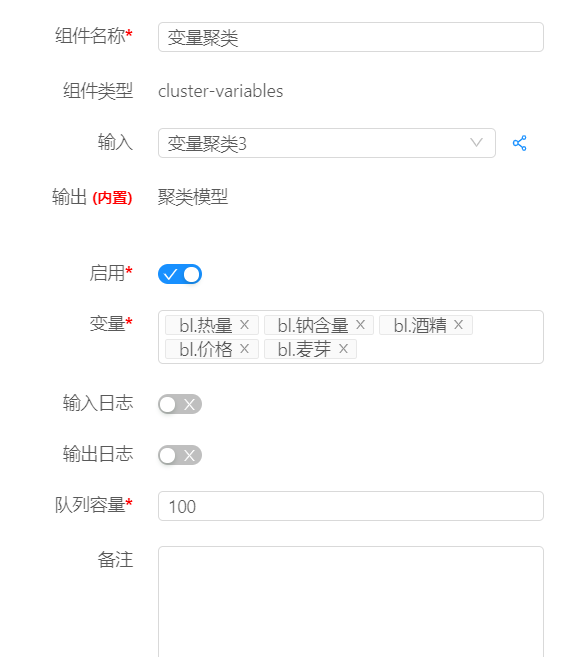

分析結果
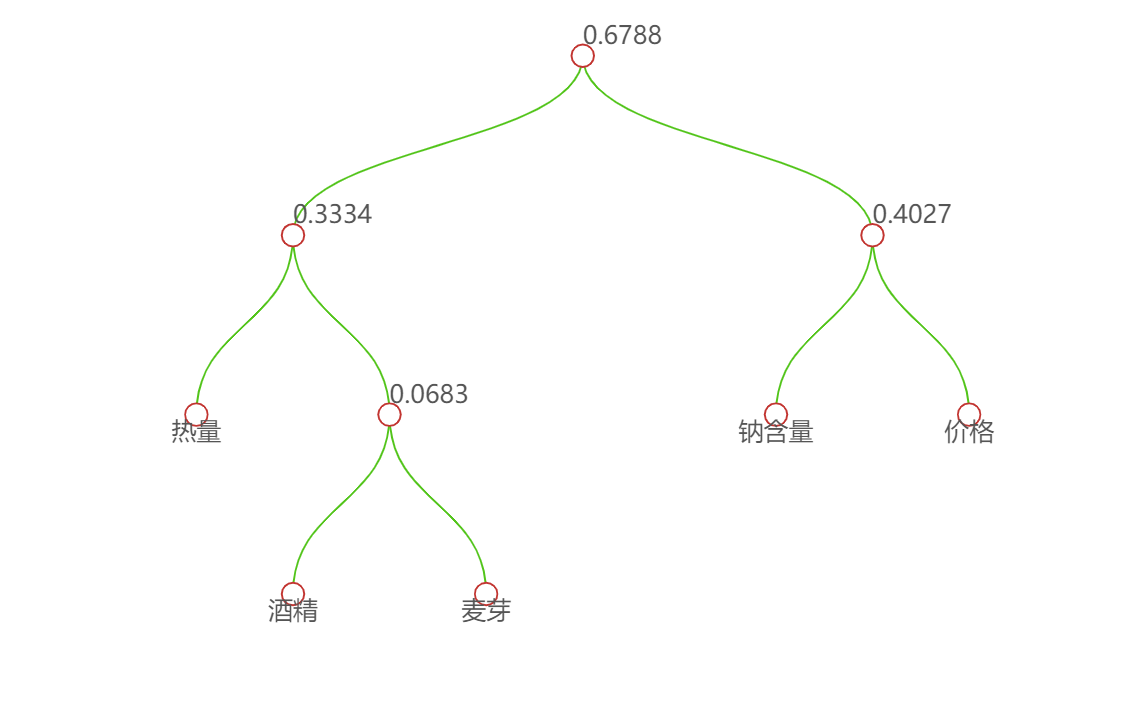
如何篩選聚類變量?現在我們有5個變量用來對啤酒分類,是否有必要將5個變量都納入作為分類變量呢?熱量、鈉含量、酒精含量,麥芽濃度這4個指標是要通過化驗員的辛苦努力來測定,而且還有花費不少成本,如果都納入分析的話,豈不太麻煩太浪費?所以,有必要對5個變量進行聚類處理。
從結果樹狀圖中可以看出酒精含量與麥芽濃度兩個變量距離為0.0683,二者之間相關系數最大(相關系數等于1 - 距離)選其一即可,沒有必要都作為預測變量,導致成本增加。至于酒精含量和麥芽濃度選擇哪一個作為典型指標來代替原來的兩個變量,可以根據專業知識或測定的難易程度決定。(與因子分析不同,是完全踢掉其中一個變量以達到降維的目的。)這里選用酒精含量,至此,確定出用于預測的變量為:酒精含量,鈉含量,熱量,價格。
與國工銷售預測系統相融合
在國工銷售預測系統中,對預測因素的整理就用到了變量聚類的算法。通過變量聚類算法對影響因素的歸納整理確定最終影響系統的主要因素,降低預測的成本。
適用范圍
變量聚類可以用來:分析特征相關性 ,對指標進行分類等。
 2023-09-28
月圓人圓,國工與您賀中秋迎國慶!
2023-09-28
月圓人圓,國工與您賀中秋迎國慶!
中秋節是中國傳統節日之一,也是一年中最重要、最盛大的節日之一。在這一天,以明亮的月亮和家人團聚為特點,承載著人們無盡的思念和美好的祝福。 國慶、中秋兩節遇, 合家團圓精神俱。 團團圓圓過中秋, 歡歡喜喜
 2023-09-01
國工智能與鎂伽科技啟動戰略合作
2023-09-01
國工智能與鎂伽科技啟動戰略合作
2023年8月28日,國工智能與鎂伽科技舉行戰略合作簽約儀式,國工智能董事長柳彥宏與鎂伽科技創始人兼首席執行官黃瑜清先生代表雙方簽訂正式戰略合作協議,標志著AI輔助化工研發領先者、智能自動化實驗室引領者開啟強強聯合發展之路。&n
 2023-05-30
點亮創新發展精神火炬,勇攀人工智能科技高峰
2023-05-30
點亮創新發展精神火炬,勇攀人工智能科技高峰
創新是一個民族進步的靈魂,是一個國家興旺發達的不竭動力,也是中華民族最深沉的民族稟賦。在激烈的國際競爭中,惟創新者進,惟創新者強,惟創新者勝。 5月27日
4月6日,陜西2023年一季度重點項目觀摩活動走進渭南。當日,觀摩組深入蒲城海泰高端液晶顯示材料生產項目等重點項目建設現場進行觀摩。 作為國工智能的重要合作伙伴,近年來,

